W artykule przedstawię wprowadzenie do gRPC i GraphQL w .NET oraz omówię podstawowe różnice pomiędzy REST, gRPC i GraphQL.
GraphQL
Wprowadzenie
GraphQL został zbudowany przez Facebook w 2015 roku. Twórcy określają go jako język zapytań do API. Rozwiązanie korzysta domyślnie z POSTów (GET też jest dostępny, ale domyślnie wyłączony). Wynika to z podejścia do request’ów. Żądania dzielimy na 2 typy – zapytania i mutacje, a każde żądanie może być złożone z wielu zapytań (fragmentów) lub mutacji. W każdym żądaniu określamy również jakie pola mają być zwrócone – jak już zapewne zwróciliście uwagę może to być sporo informacji i GET typowo nie wystarczyłby do obsłużenia takiego żądania.
Zapytanie (query) to request, który powinien wyłącznie zwrócić dane bez ich modyfikacji.
W jednym zapytaniu można zawrzeć wiele podzapytań, co pokażę na przykładach.
Mutacja (mutation) to request, który modyfikuje dane. Poprzez modyfikację rozumiemy dodanie, usunięcie lub aktualizację danych.
GraphQL ma na celu przyśpieszenie budowy frontendu oraz umożliwia zwrócenie wielu informacji w jednej odpowiedzi. Technologia wspiera m.in. cache’owanie (co jest fajne), ale zawiera też jedną pułapkę, o której należy pamiętać – jeśli podepniemy bezpośrednio EF, w przypadku złożonych obiektów, dostaniemy wiele mniej złożonych zapytań, ale jest pułapką dla NoSQL o czym pisał Grzegorz Kotfis na Twitterze. Rozwiązaniem jest DataLoader o czym pisze Tomasz Pęczek na swoim blogu.
Niemniej jednak kosztem jest wysoki próg wejścia. Ponadto wersjonowanie, podobne do tego znanego z REST, jest możliwe, ale nie zalecane.
Dostępne biblioteki
Na 10.06.2022, znalazłem 5 bibliotek wartych uwagi (tzn mających więcej niż kilka gwiazdek na github), przy czym 2 z nich są szczególnie rozpoznawalne:
- graphql-dotnet
- Hot Chocolate
Dodatkowi mniejsi gracze:
- graphql-net
- Entity GraphQL
- NGraphQL
W przykładach skupię się na na Hot Chocolate 12 jako, że z tą pracowałem w przeszłości (obecnie dostępna jest już wersja 13).
Narzędzia wspomagające
Samo utworzenie endpointu jest dość proste, natomiast ręczne pisanie zapytań (query i mutation) mija się z celem ze względu na ich złożoność, dlatego też potrzebujemy narzędzi ułatwiających odpytywanie naszego GraphQL API.
Poniżej kilka popularnych narzędzi wraz z ich przeznaczeniem:
- Banana Cake Pop – desktopowa aplikacja do testowania GraphQL
- GraphiQL – narzędzie przeglądarkowe (stworzone w .NET), które pozwala na tworzenie zapytań i eksplorację schemy
- Strawberry Shake – klient GraphQL, pozwala na generowanie klienta w C#
- GraphQL Tools – zestaw pakietów npm wspomagających stworzenie serwera i klienta
- Postman – umożliwia import schema, wysyłanie zapytań, a także budowanie schema
Przykład implementacji serwera
Zaczynam od utworzenia pustego projektu w .NET Core i instalacji nugeta HotChocolate.AspNetCore. Po utworzeniu projektu, dodajemy do serwisów AddGraphQLServer() i mapujemy requesty dzięki MapGraphQL.
Początkowo całość w Program.cs wygląda następująco
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddGraphQLServer();
var app = builder.Build();
app.MapGraphQL();
app.Run();
Po uruchomieniu aplikacji, pod adresem /graphql (u mnie https://localhost:7038/graphql)znajduję się BananaCakePop, która umożliwia eksplorację lub stworzenie schematu.
Skoro mamy już pusty projekt, to warto stworzyć jakiś schemat bazodanowy, żeby gdzieś zapisać i pobrać dane. “Tradycyjnie” skorzystam z SQL Server i EF Core (model first). Jako przykład wezmę książkę (book) i autora (author) – uproszczone modele.
Żeby uruchomić migrację, stwórz pustą bazę danę, zaktualizuj połączenie do bazy danych w appsettings.Development.json, a następnie uruchom migrację:
dotnet ef database update --connection "Server=.\SQLEXPRESS;Database=graphql-demo;Integrated Security=True"
Kolejnym krokiem jest stworzenie pierwszej klasy, która będzie wspierała zapytania – w tym przykładzie jest to AuthorQuery. Po stworzeniu klasy, dodajemy do niej atrybut [ExtendObjectType(Name="Query")] możemy od razu dodać ją do GraphQL wraz z typem danych:
builder.Services.AddGraphQLServer()
.AddQueryType(x => x.Name("Query"))
.AddType<AuthorQuery>();
Takie podejście jest niezbędne dla odseparowania zapytań wg oczekiwanego schematu. Oczywiście można wszystko “wcisnąć” w jedną klasę, ale szybko nie będzie to czytelne.
Można mieć tylko jedno wywołanie AddQueryType, które definiuje zapytania, a następnie dodajemy model za pomocą extension method AddType rejestrujemy klasy z kolejnymi zapytaniami.
[ExtendObjectType(Name="Query")]
public class AuthorQuery
{
}
W kolejnym kroku to samo robimy dla klasy Book, a następnie dla autora dodajemy 2 metody – GetAuthor(int id) i GetAllAuthors() , a dla książki GetBook(int id) i GetAllBooks(). Na potrzebę demo, pomijamy stronicowanie, które przy GetAll powinno być zaimplementowane (ze względu na dużą ilość danych w “typowym” systemie). Jeśli obie metody będą nazwane identycznie, to ta z klasy zarejestrowanej później będzie widoczna.
Nim przejdziemy do zapytań, musimy dodać jeszcze DbContext:
1. Musimy je dodać do GraphQL
builder.Services.AddGraphQLServer().RegisterDbContext<DemoDbContext>()
2. Oraz sam DbContext
builder.Services.AddDbContext<DemoDbContext>(options => options.UseSqlServer(builder.Configuration.GetConnectionString("DefaultConnection")));
Dependency injection
W przypadku GraphQL, nie wstrzykujemy do konstruktora, tylko korzystając z atrybutu [Service] ustawionego w danej metody, zatem metoda GetAuthor będzie wyglądała następująco:
public async Task<Book?> GetBook([Service(ServiceKind.Synchronized)]DemoDbContext dbContext, int id)
{
return await dbContext.Books.SingleOrDefaultAsync(x => x.BookId == id);
}
Query i subquery
W domyślnej konfiguracji, pod adresem https://localhost:7038/graphql/ , dostępne jest narzędzie BananaCakePop, gdzie można podejrzeć dostępny model danych, mutacje i zapytania.

Wybieramy Browse schema i dostajemy okno konfiguracji. Wybieramy domyślne opcje i klikamy Apply.
Dostajemy następujące okno, w którym możemy eksplorować zapytania w zakładce Schema Reference
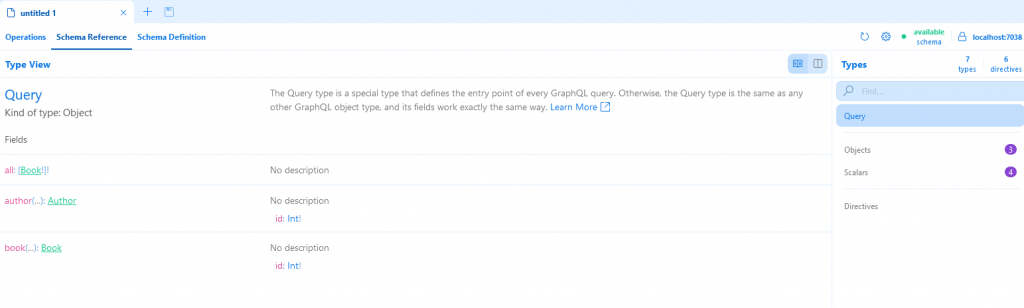
Teraz interesuje nas pierwsza zakładka – Operations.
Zbudowałem pierwsze zapytanie – chcę pobrać imię i nazwisko autora o id = 2.
query {
author(id: 2) {
firstName,
lastName
}
}
Rozkładając to na czynniki pierwsze – zaczynamy od słowa query oznaczającego nasz kontekst zapytań – mamy jeden z nazwą query. Następnie podajemy akcję – automatyczny przedrostek get z metody został usunięty – zatem zostało tylko author i parametry – w tym przypadku nazwa parametru, czyli id i jego wartość po dwukropku. Parametry muszą być nazwane, zatem próba wywołania metody bez parametrów, w sytuacji, w której są one wymagane, zakończy się błędem. Wewnątrz zapytania określamy jakie pola z modelu chcemy otrzymać.
W jednym zapytaniu można wyciągnąć dane dla kilku obiektów, przykładowo wszystkie książka i autorów:
query {
allAuthors {
firstName,
lastName
}
allBooks{
title,
isbn
}
}
Można również określić co chcemy pobrać z obiektów połączonych. W naszym przypadku mamy książki połączone z autorami.
query {
book(id: 2){
title,
isbn,
authors {
author {
firstName,
lastName
}
}
}
}
Takie zapytanie daje następującą odpowiedź:
{
"data": {
"book": {
"title": "Book title2",
"isbn": "1-233-7423-1",
"authors": [
{
"author": {
"firstName": "Stanisław",
"lastName": "Lem"
}
}
]
}
}
}
Mutacje
W kwestii dodawania mutacji, mamy podobną sytuację do Query – za pomocą AddMutationType() można dodać tylko 1 klasę, więc aby odseparować implementacje dla różnych typów i podzielić mutacje na klasy, musimy skorzystać z atrybutu ExtendObjectType. Każda mutacja musi coś zwrócić, w przeciwnym razie generowanie schematu zwróci błąd.
Po zmianach, w Program.cs rejestracja wygląda następująco:
builder.Services.AddGraphQLServer()
.RegisterDbContext<DemoDbContext>(DbContextKind.Synchronized)
.AddQueryType(q => q.Name("Query"))
.AddType<AuthorQuery>()
.AddType<BookQuery>()
.AddMutationType(q => q.Name("Mutation"))
.AddType<AuthorMutation>()
.AddType<BookMutation>();
Następnie w każdej z mutacji tworzymy metodę do usunięcia obiektu, odpowiednio RemoveAuthor i RemoveBook. Postanowiłem zwrócić bool w zależności czy udało się usunąć czy nie. Przykładowa implementacja:
public async Task<bool> RemoveBook([Service(ServiceKind.<strong>Resolver</strong>)]DemoDbContext dbContext,[ID] int id)
{
var book = await dbContext.Books.FirstOrDefaultAsync(x => x.BookId == id);
if (book != null)
{
dbContext.Books.Remove(book);
await dbContext.SaveChangesAsync();
return true;
}
return false;
}
Teraz łatwo można uruchomić mutacje w edytorze:
mutation{
removeBook(id: 2)
}
Po wywołaniu akcji odpowiedź wygląda następująco:
{
"data": {
"removeBook": true
}
}
Kod serwera do pobrania
Kod serwera jest dostępny na moim githubie: https://github.com/accent/graphql-server-demo/tree/master
Przykład wygenerowanego klienta
Do wygenerowania klienta potrzebujemy zewnętrznej biblioteki. Jako, że bazujemy na HotChocolate, to skorzystamy z ich produktu: Strawbery Shake. Instalacja odbywa się dość prosto – w command line trzeba wywołać dotnet tool install StrawberryShake.Tools --global. Następnie tworzymy pusty projekt aplikacji konsolowej i dodajemy następujące nugety:
- StrawberryShake.Transport.Http
- StrawberryShake.CodeGeneration.CSharp.Analyzers
- Microsoft.Extensions.Http
- Microsoft.Extensions.DependencyInjection
Kolejnym krokiem, dla używających Visual Studio, jest instalacja wtyczki Strawberry Shake. Dzięki temu pojawia się nowa opcja w projekcie – dodanie GraphQL Client.
Przed utworzenie klienta, należy uruchomić serwer. Poniższy zrzut ekranu pokazuje domyślne ustawienia.
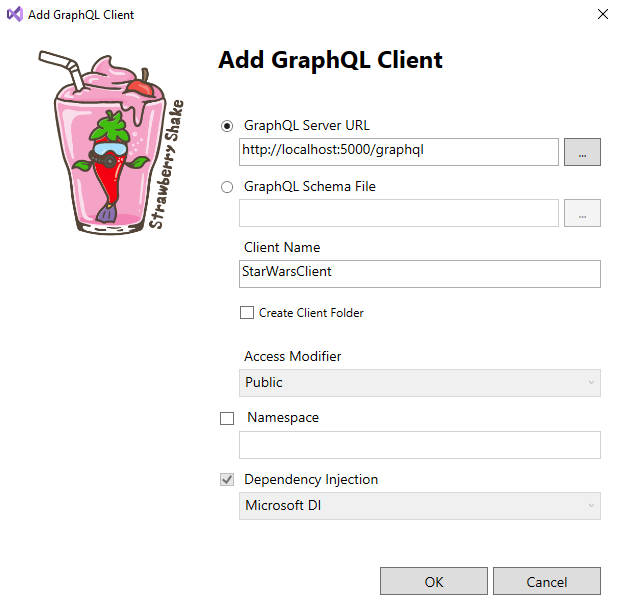
Można wskazać czy skorzystamy z serwera czy ze schema file, podać nazwę klienta i czy należy go utworzyć w osobnym folderze (polecam zaznaczyć dla wygody). Edytowalny jest również namespace – natomiast my to zostawiamy puste.
Analogicznie można wygenerować klienta korzystając linii komend: dotnet graphql init https://localhost:7038/graphql -n Demo -p ./Demo.
Jeśli tylko generowanie powiedzie się, dostaniemy następujące komunikaty:

Dzięki temu dostajemy folder o nazwie Demo, z nazwą Demo, a w nim 3 pliki: .graphqlrc.json, schema.graphql i schema.extensions.graphql.
Niestety ani zapytania ani mutacje nie generują się automatycznie, zatem musimy je utworzyć ręcznie. W tym celu tworzymy 2 pliki:
- queries.graphql
- mutations.graphql
Zapytania zdefiniowane w queries.graphql:
query GetAllAuthors{
author: allAuthors {
authorId,
firstName,
lastName
}
}
query GetAllBooks{
book: allBooks{
bookId,
title,
isbn
}
}
query GetBook($id: Int!){
book: book(id: $id){
bookId,
isbn,
title,
authors {
author{
firstName,
lastName
}
}
}
}
query GetAuthor($id: Int!){
author: author(id: $id){
authorId,
firstName,
lastName
}
}
Na podstawie tego pliku, po przebudowaniu, zostanie wygenerowany klient GraphQL. Klient zawiera wygenerowaną extension method do rejestracji DI. W przypadku tego sample to AddClient().
Całość aplikacji konsolowej z rejestracją:
using graphql_client_demo;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
var builder = Host.CreateDefaultBuilder(args);
builder.ConfigureServices(services =>
{
services.AddClient().ConfigureHttpClient(client => { client.BaseAddress = new Uri("https://localhost:7038/graphql"); });
});
var buildServices = builder.Build();
var graphqlClient = buildServices.Services.GetRequiredService<Client>();
Wszystkie metody są generowane jako properties (gettery) z danym interfejsem. Interfejs umożliwia wywołanie metody ExecuteAsync. W przypadky metod z paramterami, przekazujemy je do tej metody. Przykładowa dalsza część implementacji klienta:
var allBooks = await graphqlClient.GetAllBooks.ExecuteAsync();
foreach (var book in allBooks.Data.Book)
{
Console.WriteLine($"[{book.BookId}] {book.Title}, ISBN: {book.Isbn}");
}
var authorResponse = await graphqlClient.GetAuthor.ExecuteAsync(1);
var author = authorResponse.Data.Author;
Console.WriteLine($"Author: {author.FirstName} {author.LastName}");
Teraz przejdźmy do mutacji i tutaj istotna uwaga – jako, że w serwerze oznaczyliśmy, że przesyłami ID, to po stronie klienta należy oznaczyć pole jako typu ID, które jest konwertowane do stringa a nie int (po stronie serwera jest ID int.
Zawartość pliku mutations.graphql:
mutation RemoveBook($id: ID!){
boolean: removeBook(id: $id)
}
mutation RemoveAuthor($id: ID!){
boolean: removeAuthor(id: $id)
}
Mutacje zostaną dodane po kompilacji do klienta, analogicznie do query.
Przykładowe wywołanie mutacji:
var authorRemovalResult = await graphqlClient.RemoveAuthor.ExecuteAsync("4");
Console.WriteLine($"Author removed? {authorRemovalResult.Data.Boolean}");
Kod klienta do pobrania
Kod serwera jest dostępny na moim githubie: https://github.com/accent/graphql-client-demo/tree/master.
gRPC
Skrót gRPC pochodzi z Google RPC (Rempote Procedure Call), więc jako koncept liczy sobie kilkadziesiąt lat. Rozwiązanie pochodzące od Google powstało w 2015 roku i jest binarnym protokołem komunikacji przeznaczonym do komunikacji serwer-serwer korzystając z HTTP/2. Komunikacja może być jedno lub dwukierunkowa. Może to być typowy request-response (unary) albo stream (server, client albo dwukierunkowy).
Protokół wymaga ściśle zdefiniowanego kontraktu (w formacie Protocol Buffers [aka protobuf], w plikach .proto). Więcej o tworzeniu kontraktu w kolejnej sekcji.
Plusy wykorzystania gRPC:
- szybka komunikacja (binarna, skompresowana)
- wymuszone szyfrowanie (HTTPS)
- konieczność przestrzegania kontraktu
Istnieje jednak wyjątek co do protokołu komunikacji – istnieje biblioteka dla klientów gRPC-web, która wykorzystuje HTTP/1.1. Można ją wykorzystać zarówno w komunikacji klient-serwer jak i serwer-serwer, przy czym istnieje wiele wad takiego podejścia (m.in. szybkość, możliwość wykorzystania HTTP zamiast HTTPS itd). Decydując się na to rozwiązanie, trzeba być świadomym skutków tego podejścia, dlatego należy dobrze rozważyć wszystkie plusy i minusy tego podejścia.
Tworzenie kontraktu w C#
Są 2 metody stworzenia kontraktu:
- plik proto – domyślny sposób
- code first – korzystając z bibliotek Marca Grawell’a (protobuf-net)
W przypadku pliku proto, musimy dokładnie opisać metodę, czyli tzw call wraz z parametrami oraz klasami do jakich się serializuje.
Code first ma zdecydowanie niższy próg wejścia – potrzebujemy zrozumieć trochę mniej, ale w razie problemów, czeka nas długie szukanie pod tytułem “co poszło nie tak?”.
Składnia .proto
W pierwszym kroku definujemy wersję korzystając z instrukcji syntax.
syntax = "proto3";
Kolejnym krokiem jest określenie pakietu, do którego należy kod. Możemy również określić namespace w C#, który zostanie wykorzystany przy generowaniu kodu (instrukcja option csharp_namespace = "NAMESPACENAME";).
Po przejściu setupu, czas określić serwis (lub serwisy) jakie udostępnia i metody dostępne w ramach danego serwisu.
service SampleService {
rpc SendSample (SampleDataRequest) returns (SampleDataResponse);
}
Na koniec definiujemy model danych (message). Każdy bazowy model jest złożony z pól prostych. Dopiero w oparciu o takie modele można budować bardziej złożone typy. Żeby przekazać kolekcję, należy ją umieścić w obiekcie, nie da się inaczej zbudować złożonego typu.
message SampleDataRequest {
int32 id = 1;
}
message SampleDataResponse {
int32 id = 1;
string description = 2;
}
message SampleDataCollection {
repeated SampleData = 1;
}
Powyższy przykład, dla pola id, da w .NET nie nullowalne pole int. Do oznaczenia pola jako nullowalnego, należy skorzystać z rozszerzonego zestawu typów – w tym przypadku google.protobuf.Int32Value (wymaga dodatkowej instrukcji: import "google/protobuf/wrappers.proto". Pełna lista dla .NET jest dostępna tutaj.
Dodatkowym typem, o którym należy wspomnieć jest Dictionary – w .proto mapuje się go do `map`.
message SampleDataDictionary {
map<string, string> values = 1;
}
Code first
Podstawową pułapką jest brak uwzględnienia namespace – prowadzi to do błędów.
W przypadku klienta definujemy interfejs oznaczony atrybutrem ServiceContract z wartością Name = SERVICE_WITH_NAMESPACE. Następnie w interfejscie deklarujemy metody oznaczone atrybutem OperationContract.
[ServiceContract(Name = "API.Interfaces.SampleService")]
public interface ISampleService
{
[OperationContract]
Task<SampleDataResponse> SendSample(SampleDataRequest request, CallContext callContext = default);
}
Po stronie serwera konfiguracja wygląda niemal identycznie, jednak nie trzeba konfigurować nazwy serwisu.
W przypadku modelu definujemy go przez atrybut [DataContract] na modelu. Każdą składową określa się przy użyciu atrybutu [DataMember(Order = N)], gdzie N jest unikalnym numerem, niezbędnym do serializacji.
Code first – konfiguracja po stronie serwera
Jako pierwszy krok, należy dodać gRPC:
builder.Services.AddCodeFirstGrpc(config => { config.ResponseCompressionLevel = System.IO.Compression.CompressionLevel.Optimal; });
builder.Services.AddCodeFirstGrpcReflection();
Następnie należy dodać dodać GrpcChannel jako singleton (channel jest reużywany):
builder.Services.AddSingleton(services =>
{
var config = services.GetRequiredService<IConfiguration>();
return GrpcChannel.ForAddress(config["ApiUrl"], new GrpcChannelOptions
{
HttpClient = new HttpClient(new GrpcWebHandler(GrpcWebMode.GrpcWeb, new HttpClientHandler()))
});
});
Następnie dodajemy serwisy, które udostępnia serwer:
builder.Services.AddScoped<ISampleService>(services =>
{
var grpcChannel = services.GetRequiredService<GrpcChannel>();
return grpcChannel.CreateGrpcService<ISampleService>();
});
gRPC-Web
W przypadku gRPC-Web, konfiguracja odbywa się trochę inaczej. Dodatkowo konieczna jest konfiguracja CORS:
builder.Services.AddCors(options =>
{
options.AddPolicy("CORS",
builder => builder.AllowAnyOrigin()
.AllowAnyMethod()
.AllowAnyHeader()
.WithExposedHeaders("Grpc-Status", "Grpc-Message", "Grpc-Encoding", "Grpc-Accept-Encoding"));
});
Następnie konieczne jest wskazanie, że używamy gRPC-Web:
app.UseGrpcWeb(new GrpcWebOptions() { DefaultEnabled = true });
Umieszczamy jest pomiędzy UseRouting() i UseCors().
Na samym końcu, konfigurujemy endpointy:
app.UseEndpoints(endpoints =>{
endpoints.MapGrpcService<SampleService>().EnableGrpcWeb().RequireCors("CORS");
endpoints.MapCodeFirstGrpcReflectionService();
});
Względem wcześniej zaprezentowanego przykładu, konieczne są jeszcze 2 dodatkowe zmiany:
HttpClient = new HttpClient(new GrpcWebHandler(GrpcWebMode.GrpcWebText, new HttpClientHandler()))
Code first – konfiguracja DI po stronie klienta
Zakładając, że mamy kilka serwisów w ramach jednego serwera, najpierw należy skonfigurować GrpcChannel jako Singleton:
builder.Services.AddSingleton(services =>
{
var config = services.GetRequiredService<IConfiguration>();
return GrpcChannel.ForAddress(config["ApiUrl"], new GrpcChannelOptions
{
HttpClient = services.GetRequiredService<HttpClient>()
});
});
Dla przyśpieszenia komunikacji, kanał jest skonfigurowany raz i użyty ponownie. Następnie możemy skonfigurować wstrzykiwanie serwisów:
builder.Services.AddTransient<ISampleService>(services =>
{
var grpcChannel = services.GetRequiredService<GrpcChannel>();
return grpcChannel.CreateGrpcService<ISampleService>();
});
W przypadku konfiguracji klienta dla gPRC występuje jedna, znacząca różnica – należy dodatkowo skonfigurować klienta HTTP:
builder.Services.AddHttpClient("TestClient", client =>
{
client.BaseAddress = new Uri(builder.Configuration.GetValue<string>("ApiUrl"));
client.DefaultRequestVersion = HttpVersion.Version11;
client.DefaultVersionPolicy = HttpVersionPolicy.RequestVersionOrLower;
}).AddHttpMessageHandler<GrpcWebHandler>();
Dzięki temu, wymuszamy pracę w HTTP/1.1 zamiast 2.0.
Porównanie REST vs GraphQL vs gRPC
Poniższa tabela prezentuje najważniejsze różnice pomiędzy REST, GraphQL i gRPC.
| REST | GraphQL | gRPC | |
| próg wejścia | niski | wysoki | średni |
| HTTP/2 wymagane | nie | nie | tak (można obejść, niezalecane) |
| HTTP/3 (wsparcie) | dostępne (testowo) | dostępne (testowo) | dostępne (testowo) |
| wybór narzędzi wspomagających | bardzo szeroki | ograniczony | bardzo ograniczony |
| przeznaczenie | szeroki wachlarz zastosowań | jeden endpoint, możliwość wybrania danych z wielu źródeł w jednym zapytaniu | wysoko wydajna komunikacja pomiędzy serwerami |
| adopcja | bardzo wysoka | niska | niska |
| dokumentacja API | prosta | prosta | brak |
| format | różne dostępne, domyślnie JSON (możliwość dodania dowolnego formatera) | JSON | binarny |
| support | szerokie wsparcie community | bardzo mało ludzi zaznajomionych, możliwość wykupienia płatnego wsparcia u wybranych dostawców bibliotek | bardzo mało ludzi zaznajomionych, brak płatnego wsparcia |